안녕하세요. 게임개발자 놀이터 입니다.
이전 포스팅에 이어 웹크롤링에 대해서 포스팅 하고자 합니다
웹에서 정보 가져오기 - 1
저번에 requests 설정까지 마무리 했습니다.
그럼 이제 requests가 정상 작동하는지 확인해봅시다.
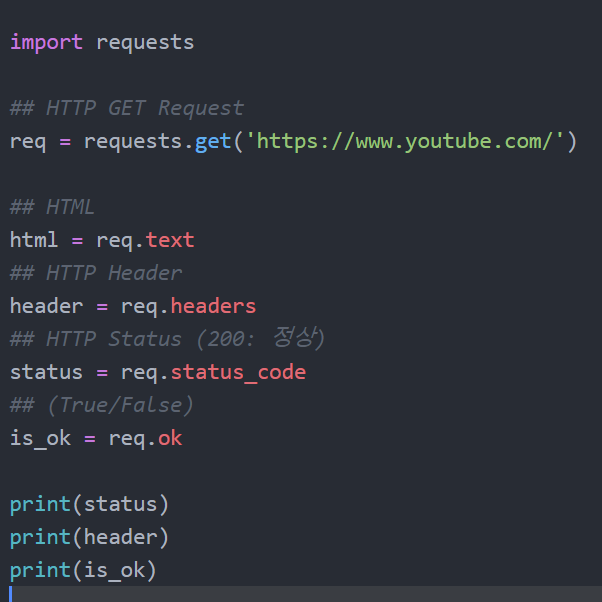
이와 같이 소스를 입력 한 후 빌드 ( 컨트롤 + 쉬프트 + B ) 를 해봅시다.
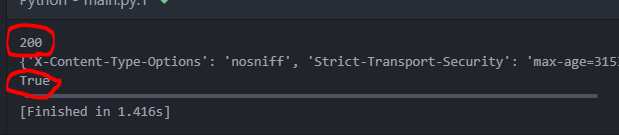
status_code 값과 OK 값이 200, true가 나온다면 성공입니다.
하지만 html 텍스트는 현재 읽을 수 없습니다.
html을 읽기 위해선 다음과 같은 세팅이 필요합니다.
BeautifulSoup
html의 내용을 파이썬에서 사용할 수 있도록 파싱 해주는 패키지 입니다.
명령 프롬프트 창을 이용해 bs4를 설치 해줍니다.
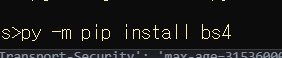
이제 html을 파싱할 수 있습니다.

위처럼 소스를 입력하고 빌드하시면 HTML 소스가 로그창에 출력 된걸 확인 하실 수 있습니다.
데이터 검색
테스트에 사용 할 HTML URL입니다. : https://www.google.com/search?q=+site:tistory.com+%EC%8B%9C%EB%A6%AC%EC%8B%9C%EC%95%88&sa=X&ved=2ahUKEwjuofzmjoLlAhWUE4gKHS-wAYEQrAN6BAgGEBQ&biw=2048&bih=1042
구글 페이지에서 [site:tistory.com 시리시안] 을 검색한 URL입니다.
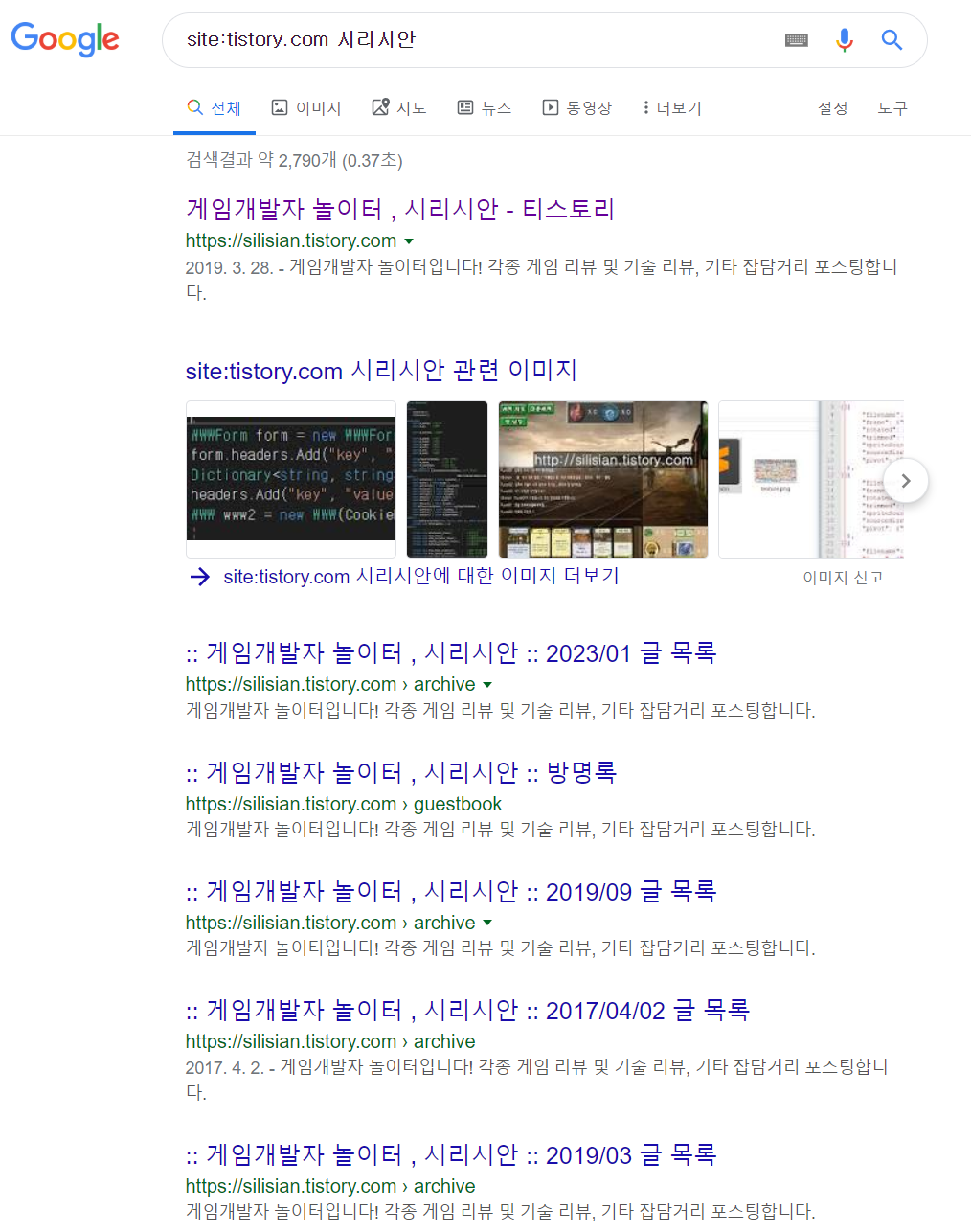
이곳에서 저는 검색 제목만 모아서 크롤링 해보려 합니다.
크롬에서는 검사 기능을 통해 바로 HTML을 볼 수 있습니다.
찾고자 하는 글에 우클릭 후 검사를 눌러 줍니다.
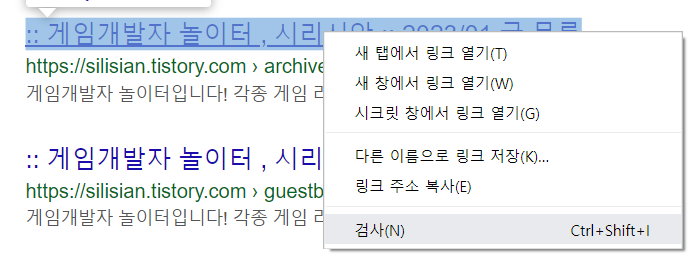
검사를 누르면 우측에 HTML 창이 뜨게 됩니다.
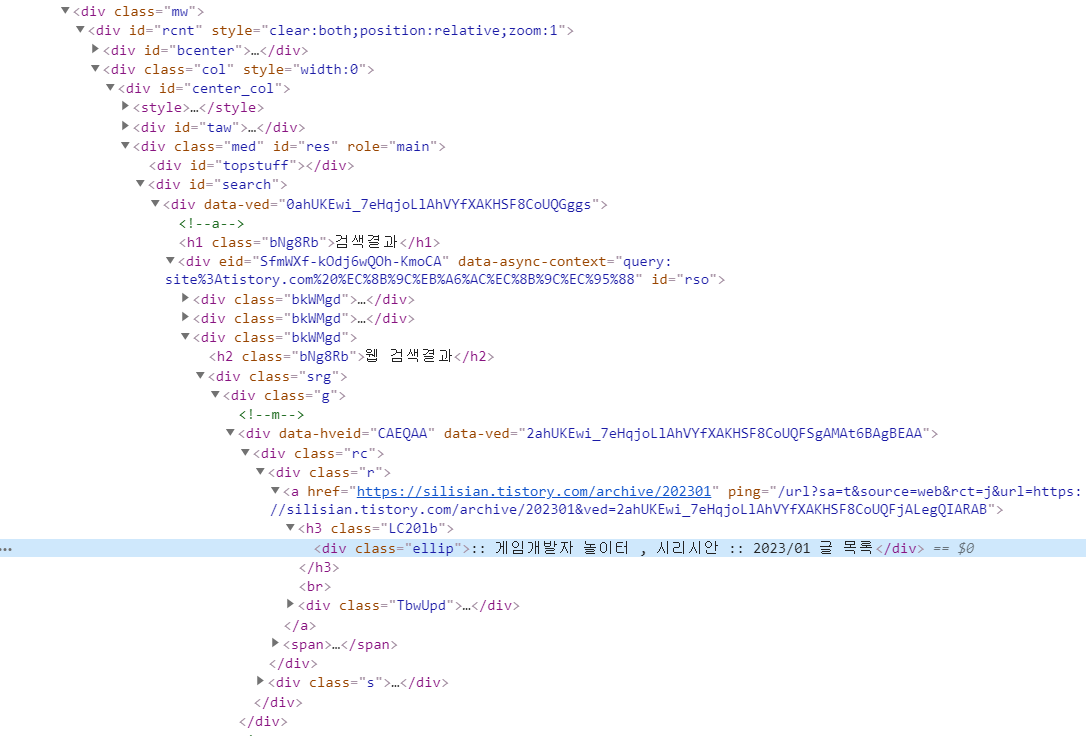
내용을 보니 저 검색결과는 div 태그에 class 'ellip'를 가지고 있군요. 이 정보를 이용해 파싱해 찾아 봅시다.
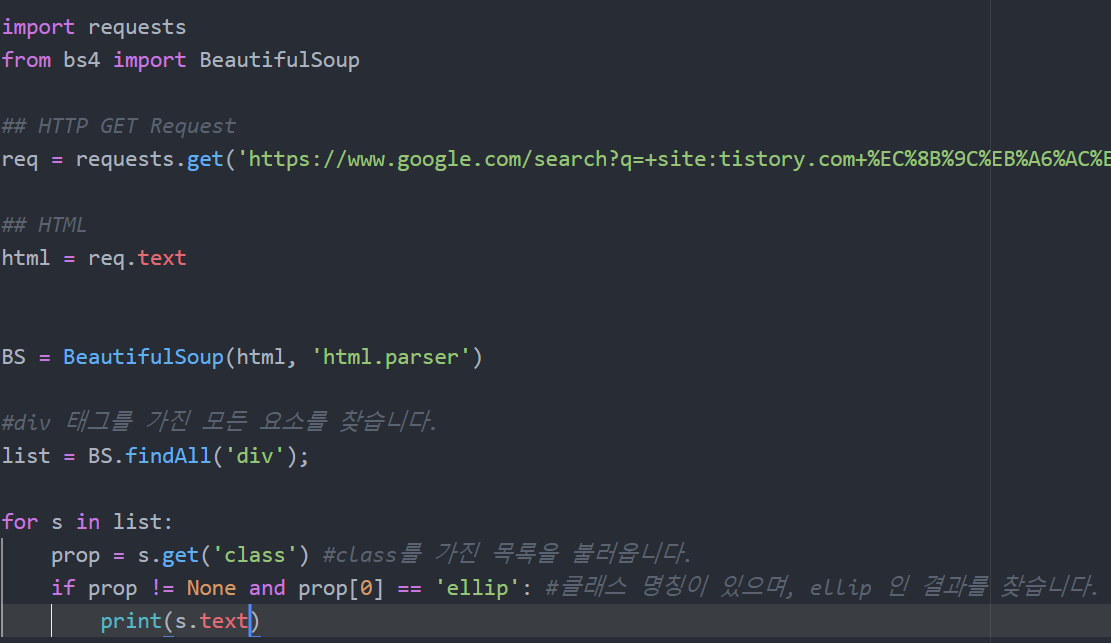
전체 소스입니다. 중간에 잘린 url은 위에 적용된 HTML입니다.
빌드 해보니 아무런 결과가 나오지 않았습니다. 아무래도 클래스 명칭 'ellip' 로 찾는게 문제 인거 같네요.
정확한 HTML 비교를 위해 prettify() 로 HTML을 출력 해봤습니다.

클래스 명칭이 다르네요, 아무래도 검색할때 생성되는 구조이거나 랜덤으로 만들어지는거 같습니다. 따라서 클래스 비교 방식은 사용 할 수 없겠군요.
이번엔 글 제목을 클릭해서 들어 갈 수 있으니, a 태그로 찾은 후 div로 분류해봤습니다.
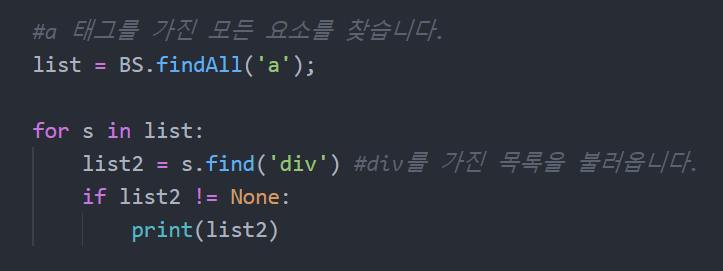
출력되는 list2를 확인해보니 아래와 같았습니다.
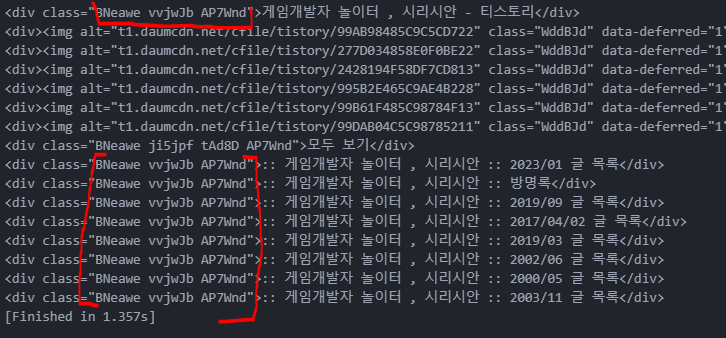
첫번째 검색결과와 제가 필요했던 애들의 클래스 명칭이 전부 똑같네요. 이건 이용할 수 있을꺼같습니다.
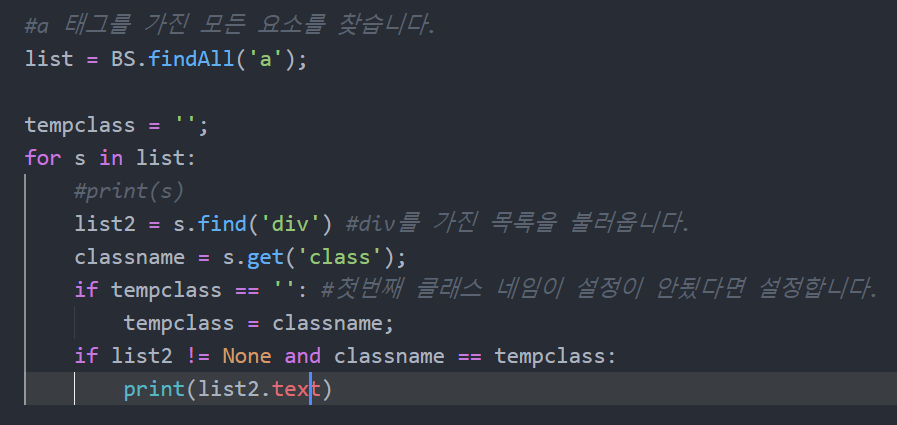
첫번째 클래스 명칭을 이용해 찾도록 수정했습니다.
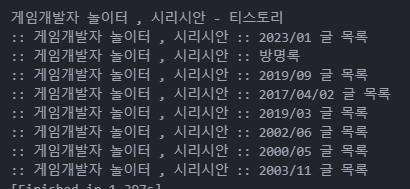
제가 얻고자 했던 목록들만 얻을 수 있게 되었습니다.
이처럼 크롬의 HTML을 분석하여 원하는 정보를 찾을 수 있습니다. 구글의 경우 위와 같았지만, 다른 사이트의 경우엔 분석이 우선시 되니, HTML 을 읽는 기술이 필요할꺼 같습니다.
감사합니다.
'프로그래밍 > Language' 카테고리의 다른 글
| [Python] 파이썬 프로그래밍 - 02 웹크롤링 / Request 설치와 ATOM 세팅 [Python Web Crewling] (0) | 2019.10.04 |
|---|---|
| [Python] UnicodeEncodeError: 'cp949' 에러 (1) | 2019.10.04 |
| [Python] 파이썬 프로그래밍 -01 ATOM 설치 (Python) (0) | 2019.10.04 |
| [C++] 이벤트 콜백 함수(Button)만들기! (1) | 2017.04.06 |
| [C언어] 변수 선언시 저장 공간에 대하여 (0) | 2017.03.29 |
